4. Expresiones regulares (regex)¶
En esta parte del curso veremos el tema de regex. Este tutorial tiene un enfoque general, sin aplicaciones en Bioinformática (lo que veremos más adelante), pero si entiendes bien los fundamentos y ejercicios que te presentamos en esta parte, no tendrás problemas con aplicar luego en los ejercicios de Bioinformática que te presentaremos más adelante.
Nota importante
En la mayoría de secciones existen preguntas y pequeños ejercicios, maracados con la etiqueta Pregunta, cuyas respuestas deben ser realizadas como deber de esta parte del curso. Debes guardar las respuestas en una celda del Jupuyer notebook (en formato Markdown) que debes entregar en este capítulo. A continuación te dejamos un ejemplo de cómo esperamos que realices esto:
Respuestas de os ejercicios de expresiones regulares
4.4
4.5
…
Luego de la fecha de entrega del deber enviaremos las respuestas a los ejercicios de todas las secciones.
4.1. ¿Qué son las regex?¶
Una regex es una cadena de caracteres (string) especial que describe patrones de búsqueda sobre otros strings. Para el procesamiento de las regex se utilizan diferentes engines, que tienen pequeñas variaciones de una aplicación a otra. Generalmente, se usan para extraer información de texto en muchos de lenguajes de programación, editores de texto y herramientas de procesamiento de texto de terminal como grep y sed (lo que veremos en temas posteriores).
4.2. Engine de regex y texto para este tutorial¶
En este tutorial usaremos este servidor en línea para probar los regex que crearemos. Existen varias engines disponibles, en este caso usaremos la PCRE2 (PHP >=7.3), que se selecciona en la sección flavor. El texto con el que vamos a trabajar es parte de la letra de la canción Contrapunto para Humano y Computadora de la banda El Cuarteto de Nos:
Fecha:15/03/20
Código: 00112233
[Verso 1:Roberto]++++
La primera es la vencida
La tercera es la tercera
Así que reto a cualquiera
Que conmigo aquí se mida
Quien acepte es un suicida
Que se sobrevalora
Porque nadie me vence ahora
Ni el coplero campeón mundial
Ni un rapero de freestyle
Ni
Ni la mejor computadora
[Verso 2:computadora]***
¿Ni la mejor computadora?
¿Ni la mejor Computadora?
¿Lo dice usted que es un simple humano?
Se muestra tan ufano
Pero le llegó la hora
Porque su ego lo devora
Y se cree superior a ultranza
Pero con una muestra alcanza
Hoy las bombas que crearon sus mentes
Son más inteligentes
Que los idiotas que las lansan
[Verso 3:Roberto]++**
Los idiotas que las lanzan
A mí no me representan
Pero a los que las inventan
Quizás debas tu confianza
Y aunque parezca chanza
Tu vida es por su invención
Y digo vida con compasión
A un rejunte irrazonable
De circuitos, chips y cables
Sin alma ni corazón
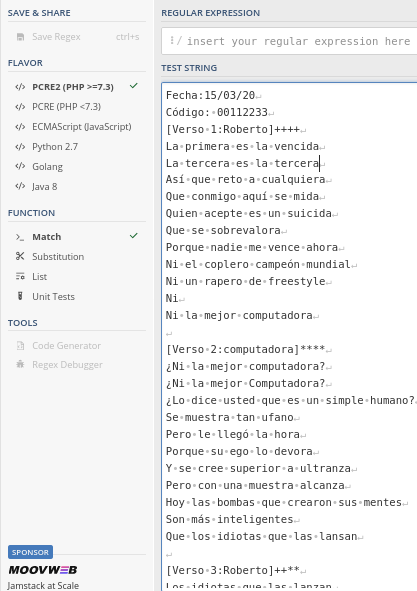
Entonces, el primer paso es copiar el texto de la canción en la sección TEST STRING del servidor en línea, verificar que la engine de regex sea la PCRE2 (PHP >=7.3) y que en la sección FUNCTION esté seleccionada la opción Match, como se muestra en la siguiente captura de pantalla:
4.3. Flags¶
De forma general, las regex se representan de la siguiente forma /patrón_de_búsqueda/, en la que el patrón de búsqueda está delimitado por barras invertidas /. Luego de la regex escrita de esta forma se pueden añadir flags, que son modos en los que se buscan las coincidencias de las regex. En la mayoría de de engines están disponibles los siguientes modos:
g (global): No termina luego de la primera coincidencia, reiniciando las búsquedas posteriores desde el final de la coincidencia anterior
m (multi-line): Los símbolos
^yscoinciden con el inicio y fin de línea respectivamente.s (single-line): El símbolo punto
.coincide con el caracter de inicio de línea\ni (case-insensitive): Hace que la regex no sea sensible a mayúsculas o minúsnuclas. La regex
\abc\icoincide con el patrón AbC.
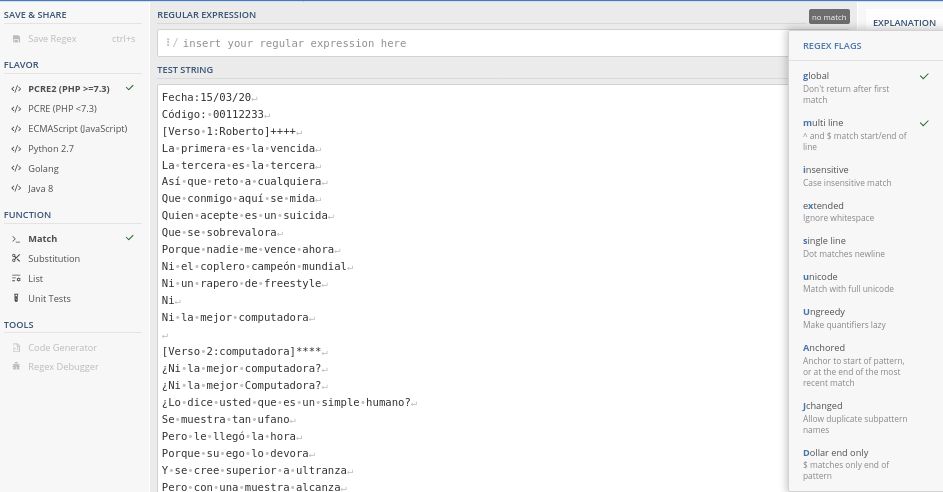
Se pueden activar varios flags a la vez. Se debe considerar que existen otras flags, pero estas son específicas de diferentes engines. En el servidor en línea que usaremos en este tutorial pueden configurar las flags en la sección REGEX FLAGS, que se encuentra a la derecha del buscador de regex. Para realizar los ejercicios de este tutorial deben activar las flags g y m, como se muestra a continuación:
4.4. Caracteres literales¶
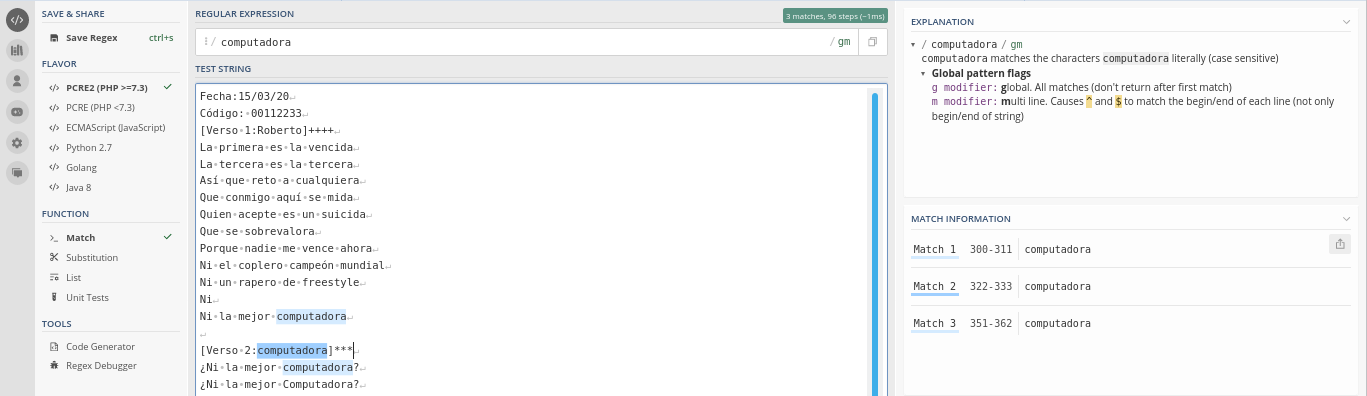
Las regex más simples son aquellas que buscan caracteres de forma literal, por ejemplo busquemos la palabra computadora en el texto de trabajo.
Pregunta
¿Cuántas coincidencias encontraste con esta palabra?
Se debe considerar que la mayoría de engines de regex son sensibles a mayúsculas (case-sensitive) por defecto. Por tanto, en el ejemplo no se identificó la palabra Computadora.
Pregunta
¿Cómo puedes hacer para que la engine de regex no sea sensible a mayúsculas?
Nota
Noten que luego de añadir una expresión regular, en la parte derecha del servidor en línea se presenta una explicación sobre la regex, y las posiciones del texto que coincidieron con la regex, com se muestra a continuación:
4.4.1. Metacaracteres¶
El mayor potencial de las regex está dado por el uso de caracteres especiales que permiten buscar expresiones que no son literales, que se conocen como metacaracteres y se utilizan para respresentar otros caracteres. Los metacaracteres más usados incluyen:
Metacaracter |
Símbolo |
|---|---|
Corchete de apertura |
|
Paréntesis de apertura y cierre |
|
Barrra invertida |
|
Símbolo de potencia |
|
Signo de dolar |
|
Punto |
|
Pipe |
|
Símbolo de pregunta de cierre |
|
Asterisco |
|
Símbolo de suma |
|
Y qué pasa si queremos buscar un patrón que incluya un metacaracter como computadora?.
Pregunta
¿Esta regex funciona?
Se observa que no se incluye el símbolo ?. Si se desea buscar alguno de los metacaracteres de forma literal se deben escapar, para lo que se emplea la barra invertida \. Entonces, para encontrar el patrón que queremos debemos usar la regex computadora\?. Esto aplica con todos los metacaracteres mencionados.
Nota
Noten que tres de los metacaracteres de regex (* ? []) tabién se usan como wilcards generales en comandos de Bash, pero debemos tener en cuenta que sus aplicaciones son diferentes. En este blog hay una discusión sobre sus diferencias.
4.4.2. Caracteres especiales de espacios en blanco: \t \r \n \v¶
En las regex se pueden añadir secuencias de caracteres especiales para colocar espacios en blanco, que no se imprimen y sirven para dar formato al texto. Algunos de estos caracteres más usados son:
Metacaracter espacios en blanco |
Símbolo |
|---|---|
Tabulador |
|
Retorno de carro |
|
Nueva línea |
|
Tabulador vertical |
|
4.5. Conjuntos o clases de caracteres¶
4.5.1. Expresiones de corchetes y rangos: []¶
Se usan para buscar ciertos caracteres de interés. Para esto se deben poner los caracteres de interés entre corchetes []. Por ejemplo, si queremos buscar los caracteres a o e usamos la regex [ae]. Además, si queremos encontrar las palabras que tengan los caracteres an seguido de una letra o o z como humano, ufano, ultranza, o confianza; usamos la regex an[oz].
Un punto importante es que el orden de de los caracteres dentro de la clase de caracteres no importa, por lo que en el anterior ejercicio da lo mismo si usamos la regex an[zo]. Esto puede ser útil para encontrar palabras con faltas ortográficas.
Pregunta
¿Cuál regex podrías usar para mapear las palabras lanzan y lansan en el texto?
Dentro de las clases de caracteres es posible definir rangos, para lo que se usa un guión -. Por ejemplo, si queremos encontrar los caracteres numéricos del texto podemos usar la regex [0-9]. Se debe considerar que la regex [0-9] busca dígitos simples entre 0 y 9.
Es posible buscar más de un rango dentro de clases de caracteres. Por ejemplo, si se quieren encontrar caracteres alfanuméricos que incluyan mayúsculas, podemos usar la regex [0-9a-zA-Z].
Pregunta
¿Qué regex se puede usar para encontrar las letras minúsculas de la d a p, mayúsuculas de la Q a W, y los números de 1 a 3?
4.5.2. Negación de expresiones de corchetes y rangos: [^]¶
Para negar la expresiones de corchetes se añade el símbolo de potencia ^ después del corchete de apertura [. Esto permite buscar cualquier caracter que no esté en la clase de caracteres. Se debe considerar que esta operación va a seguir buscando un caracter. Por ejemplo, la regex an[^oz] busca los caracteres an seguido de un caracter que no sea la letra o o z,
Pregunta
¿Cuáles palabras coinciden con este patrón? ¿Cuáles caracteres se están identificando en estas palabras con la negación de clase de caracteres empleada?
4.5.3. Metacaracteres dentro de expresiones de corchetes y rangos: ] \ ^ -¶
Los metacaracteres que son válidos dentro de expresiones de corchetes son:
Metacaracter dentro de expresiones |
Símbolo |
|---|---|
Corchete de cierre |
|
Barrra invertida |
|
Símbolo de potencia |
|
Guión |
|
El resto de metacaracteres se comportan como caracteres normales, por lo que no es necesario usar el caracter de escape \ para buscarlos dentro de las expresiones de corchetes.
Pregunta
Si queremos buscamos los símbolos asterisco * o suma +, ¿Cuál regex podríamos usar?
4.5.4. Abreviaciones de expresiones de corchetes y rangos: \d \D \w \W \s \S¶
Debido a que muchas clases de caracteres se usan de forma frecuente, existen algunas abreviaciones de estas:
Abreviación expresión de corchetes |
Descripción |
|---|---|
|
Números |
|
Negación de números |
|
Caracteres de palabras |
|
Negación de caracteres de palabras |
|
Caracteres de espacios |
|
Negación de caracteres de espacios |
Se debe consdierar que las abreviaciones de clases de caracteres se pueden usar dentro de corchetes o fuera de estos.
Pregunta
Con los conocimientos que tienes hasta ahora, ¿Cómo buscarías con una sola regex los strings Verso 1:Roberto y Verso 2:computa en el texto?
4.5.5. Metacaracter punto: .¶
El metacaracter punto . coincide con un caracter simple, cualquiera que este sea. La única excepción que el punto no busca es el caracter de inicio de nueva línea \n,
Pregunta
¿Qué flag podríamos usar para modificar este comportamiento?
El metacaracter punto debe ser usado con cautela, ya que puede crear coincidencias con errores. Por ejemplo, si queremos buscar fechas escritas en formato mm\dd\yy, pero con cualquier separador (guiones, espacios, etc), podríamos usar la regex \d\d.\d\d.\d\d. Si pruebas esta regex se observa que encontró la fecha de modificación del texto, pero también el código 00112233, lo que es un resultado no deseado.
Pregunta
¿Se te ocurre una forma de mejorar esta regex para mapear solamente las fechas en formato **mm\dd\yy?
4.6. Anclas y límites ¶
Las anclas y límites permiten identificar strings considerando su posición en el texto (antes, después o entre caracteres), en lugar de caracteres específicos como los temas vistos antes.
4.6.1. Anclas de inicio y final de línea: ^ $¶
Permiten identificar texto al inicio (^) o al final ($) de las líneas de un texto.
Pregunta
¿Cuál flag debe estar habilitada para que funcionen las anclas al inicio y final de todas las líneas?
Por ejemplo, si queremos buscar todas las líneas que empiecen con la palabra Ni, debemos usar la regex ^Ni.
Pregunta
Por otra parte, si queremos buscar las líneas que terminen con la palabra computadora, debemos usar la regex computadora$, ¿Usando esta regex, es identificada la línea que termina con computadora??
Si queremos buscar líneas que empiecen con la palabra Ni y terminen con la palabra computadora, sería lógico usar la regex ^Ni computadora$, ¿Esta regex funciona?
Nota
Para realizar esta búsqueda debemos usar cuantificadores y otros caracteres especiales, lo que revisaremos en las siguientes secciones.
4.6.2. Anclas de inicio y final del texto: \A \Z¶
Permiten buscar texto solamente al inicio (\A) o al final del texto (\Z).
Pregunta
Por ejemplo, si queremos buscar la fecha del texto incluyendo la palabra Fecha, que esta solamente al inicio, ¿Cuál regex podríamos usar?
Si queremos verificar si al final del texto está la palabra corazón, ¿Cuál regex deberíamos usar?.
4.6.3. Límites de palabras: \b \B¶
El metacaracter \b permite buscar posiciones que se conocen como límites de palabras. Hay cuatro posiciones que califican como límites de palabras:
Antes del primer caracter en un string, si el primer caracter es un caracter de palabra.
Después del último caracter en un string, si el último caracter es un caracter de palabra.
Entre un caracter de palabra y un caracter que no es palabra seguido por la derecha de un caracter de palabra.
Entre un caracter que no es palabra y un caracter de palabra seguido por la derecha de un caracter que no es de palabra.
En términos simples, \b permite buscar palabras que comiencen y terminen con ciertos caracteres con las regex \bpalabra y palabra\b respectivamente, o que busquen solamente una palabra determinada con \bpalabra\b. Los caracteres de palabras son identificados con la regex \w y los de no palabras con \W, pero se pueden añadir otros caracteres dependiendo de la engine de regex que se utilice.
Por ejemplo, si queremos buscar las palabras que empiecen con ra podemos usar la regex \bra, aquellas que terminen con or coincidirán con or\b, y si queremos buscar solamente la palabra se funcionará \bse\b. Prueben estas regex y observen las diferencias al buscar estas expresiones de forma literal como ra, or, y se. ¿Cuáles son ejemplos de palabras no se incluyen al usar los límites de palabras comparado con la búsqueda literal?
La negación de los límites de palabras es \B, que busca todas las posiciones que no coincidan con \b. Por tanto, la negación permite buscar palabras que NO empiecen, terminen o sean ciertos caracteres con las regex \Bpalabra, palabra\B y \Bpalabra\B respectivamente.
Pregunta
Realiza las mismas búsquedas que hiciste antes pero usando la negación, ¿Los resultados coinciden con lo que esperabas?
4.7. Metacaracter de alternancia: |¶
Al igual que las expresiones de corchetes de las clases de caracteres, el metacaracter pipe | sirve para buscar una regex de un conjunto de opciones posibles. Si replicamos los ejemplos de la sección de expresiones de corchetes, para buscar los caracteres a o e debemos usar la regex a|e.
Pregunta
Prueba esta regex y comparala con el resultado obtenido con la expresión de corchetes [ae]. ¿Coinciden ambos resultados?
Ahora, para replicar el ejemplo en el que buscamos las palabras que tengan los caracteres an seguido de una una letra z u o, sería lógico usar la expresión anz|o. ¿El resultado de esta regex coincide con lo que se obtuvo usando la regex an[zo]?
Si lo comprobaste, estás de acuerdo con nosotros en que los resultados no coinciden, ¿Qué pasó?. Esto ocurrió porque este operador posee el más bajo nivel de precedencia de los operadores de regex, por lo que busca todo lo que esté a la izquierda o todo lo que esté a la derecha del pipe.
Nota
Para corregir esto debemos usar metacaracteres de agrupación, lo que veremos con más detalle en la última sección.
4.8. Metacaracteres de repetición o cuantificadores: ? + * {}¶
Permiten especificar el nÚmero de veces que un caracter o caracteres de una regex debe aparecer en un string.
4.8.1. Metacaracter de cero-o-una repetición: ?¶
El metacaracter ? hace que el caracter o caracteres previos se repitan cero o una vez, o que este sea opcional.
Pregunta
Por ejemplo, si usamos la regex compu?, ¿Cuál palabra del texto que no sea compuatora que coincide con la búsuqeda?
4.8.2. Metacaracteres de cero-o-más y una-o-más repeticiones: * +¶
El metacaracter * hace que el caracter o caracteres previos se repitan cero o más veces; mientras que el + hace que se repitan una o más veces.
Pregunta
Por ejemplo, si queremos buscar el contenido de todas las líneas que empiecen con Ni podemos usar las regex ^Ni[\w ]* o ^Ni[\w ]+. Verifica los dos casos e identifica cuál es la diferencia entre ambas, ¿Hay alguna línea que se identifica con una regex pero no con la otra?
Con los conocimientos que hemos adquirido hasta ahora, ya podemos resolver el problema que dejamos pendiente en la sección 4.6.1, en el que queríamos buscar todas las líneas que empiecen con Ni y terminen con computadora. ¿Cuál sería la regex para este caso?
¿Cómo modificarías la regex de la pregunta anterior para incluir las líneas que empiezan con un caracter como ¿ u otro, seguido de Ni, y que terminen con computadora seguido de ? u otro caracter?
4.8.3. Metacaracteres de intervalos de repeticiones: {}¶
Si queremos especificar el número de repeticiones del caracter o caracteres previos que se repiten en la regex podemos usar los metacaracteres {}. Su uso es de la siguiente forma {min, max}, donde min un número entero positivo que indica el número mínimo de coincidencias, y max es un entero igual o mayor que min e indica el número máximo de coincidencias. Los metacaracteres * y + serían equivalentes a {0, } y {1, } respectivamente.
Pregunta
Por ejemplo, podríamos usar esta estrategia para encontrar en el texto todos los números que estén entre 10 y 999. ¿Cómo crearías la regex que permita realizar esta búsqueda?
4.9. Metacaracteres de agrupamiento: ()¶
Los metacaracteres () permiten agrupar partes de una regex, lo que permiete aplicar diferentes operaciones al grupo.
Pregunta
En la sección 4.7 observamos que la regex anz|o no funcionó igual que an[zo], y se mencionó que esto se puede solucionar usando metacaracteres de agrupación; con lo que la regex quedaría así an(z|o). Realiza de nuevo la verificación, ¿Ahora si coincidieron los resultados entre an[zo] y an(z|o)?
Los cuantificadores también se aplican a grupos de caracteres. Por ejemplo, si usamos la regex an(z|o) incluyendo el operador cero-o-una repetición an(a|z)?, ¿Cambian los resultados previos?
¿Cuáles palabras nuevas que incluyen este patrón aparecen?
Puedes probar este concepto con los otros cuantificadores y verificar su funcionamiento. Los metacaracteres de agrupamiento permiten realizar operaciones más complejas como backreferences, lo que no vamos a explicar en este tutorial pero pueden revisar en el material suplementario de la siguiente sección.
4.10. Material suplementario¶
Si quieren aprender temas más especializados sobre regex pueden usar el libro Regular Expressions: The Complete Tutorial, que se puede obetener de forma libre usando el siguiente link. La mayoría de los contenidos de esta parte se obtuvieron de este libro.
Otras páginas web útiles sobre este tema: